

TL;DR:
- Computer Vision interpretiert Bilddaten automatisch, aber ist komplexer als menschliches Sehen.
- Herausforderungen wie Domain Shift und Edge Cases erfordern robuste Strategien im Einsatz.
- Einsatzbereiche reichen von Industriequalitätssicherung bis zu AR-basiertem Lernen in Bildung.
Computer Vision gilt als eine der faszinierendsten Technologien unserer Zeit. Auf den ersten Blick scheint es, als würden Maschinen einfach „sehen" wie Menschen. Doch die Realität ist überraschend anders und weitaus komplexer. Wer Computer Vision für Unternehmensanwendungen oder Bildungsprozesse einsetzt, trifft schnell auf Hürden, die in Demos und Präsentationen kaum sichtbar werden. Wir bei Amlogy begleiten Unternehmen und Bildungseinrichtungen täglich dabei, diese Technologie sinnvoll zu nutzen, und wissen: Wer die Grundlagen, Grenzen und Möglichkeiten von Computer Vision wirklich versteht, trifft bessere Entscheidungen für die digitale Zukunft.
Inhaltsverzeichnis
- Definition und Grundprinzipien von Computer Vision
- Typische Herausforderungen: Edge Cases und Domain Shift
- Benchmarking und Evaluierung: Leistung richtig messen
- Computer Vision im Alltag: Praxisbeispiele und Anwendungsszenarien
- Redaktioneller Einblick: Die unterschätzte Komplexität von Computer Vision
- Mehr Wert durch AR und Computer Vision: Lösungen für Unternehmen und Bildung
- Häufig gestellte Fragen
Wichtige Erkenntnisse
| Punkt | Details |
|---|---|
| Pipeline-Prinzip verstehen | Computer Vision verwendet Vorverarbeitung, Feature-Extraction und Deep Learning für automatische Bildanalyse. |
| Fehlerquellen kennen | Edge Cases und Domain Shift sind zentrale Herausforderungen für die Zuverlässigkeit in realen Anwendungen. |
| Benchmarks richtig wählen | Domänenspezifische Tests und geeignete Benchmarks sind entscheidend, um echte Leistungsfähigkeit zu bewerten. |
| Praxisnahe Anwendungen | Computer Vision lässt sich erfolgreich in Automatisierung, AR-Schulungen und Qualitätskontrollen nutzen. |
| Mythen hinterfragen | Computer Vision ist keine Nachbildung menschlicher Sicht; robustes Design ist erforderlich. |
Definition und Grundprinzipien von Computer Vision
Computer Vision (auf Deutsch: Maschinelles Sehen) bezeichnet die automatische Interpretation und Analyse von Bilddaten durch Algorithmen und künstliche Intelligenz. Das Ziel ist es, dass Maschinen aus Fotos, Videos oder anderen visuellen Eingaben nützliche Informationen extrahieren, genau so wie ein Mensch ein Bild analysiert und versteht. Doch während das menschliche Gehirn diese Leistung mühelos und intuitiv erbringt, brauchen Maschinen klare Strukturen, große Datenmengen und präzise Trainingsprozesse.
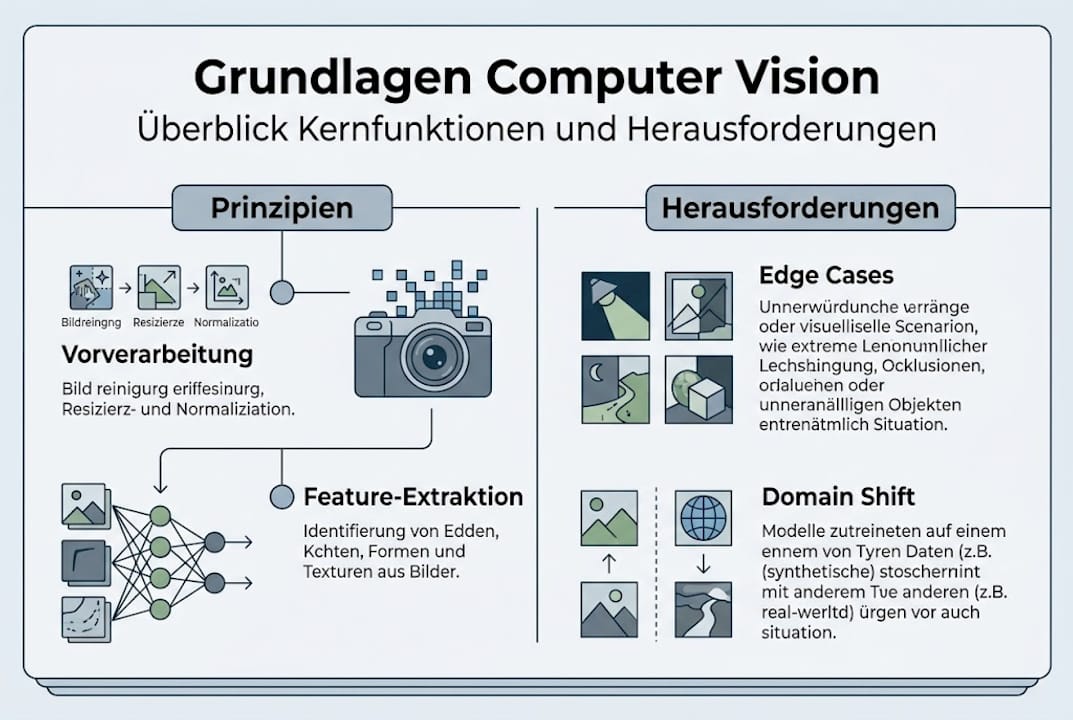
Der Kern von Computer Vision liegt im sogenannten Pipeline-Ansatz. Pipeline-basierte Verarbeitung umfasst typischerweise drei zentrale Stufen: Vorverarbeitung und Standardisierung der Bilddaten, Feature-Extraktion sowie Deep-Learning-basierte Modelle für Aufgaben wie Erkennung, Klassifikation, Segmentierung oder 3D-Rekonstruktion. Jede dieser Stufen hat eigene Anforderungen und potenzielle Fehlerquellen.
Was leistet Computer Vision konkret? Hier ein Überblick über typische Aufgaben:
- Erkennung (Detection): Ein Objekt oder eine Person wird im Bild lokalisiert, zum Beispiel Fahrzeuge auf einem Parkplatz oder Defekte auf einer Produktionslinie.
- Klassifikation (Classification): Das Modell ordnet ein Bild einer Kategorie zu, etwa „gesundes Bauteil" oder „fehlerhaftes Bauteil."
- Segmentierung (Segmentation): Jeder Pixel im Bild wird einer Klasse zugeordnet, was besonders in der medizinischen Bildgebung oder im autonomen Fahren wichtig ist.
- 3D-Rekonstruktion: Aus mehreren 2D-Bildern wird ein dreidimensionales Modell erzeugt, was für 3D-Visualisierung in Training und Kommunikation besonders wertvoll ist.
Der aktuelle Standard in der Computer Vision sind sogenannte Convolutional Neural Networks (CNNs) und ihre Weiterentwicklungen wie Transformer-Architekturen. CNNs sind darauf spezialisiert, räumliche Strukturen in Bildern zu erkennen, weil sie lokale Muster wie Kanten, Texturen und Formen hierarchisch lernen. Transformer-Modelle hingegen verarbeiten Bilder als Sequenzen von Patches und liefern oft bessere Ergebnisse bei komplexen Szenen.
| Aufgabentyp | Beispielanwendung | Typische Architektur |
|---|---|---|
| Erkennung | Qualitätskontrolle in der Fertigung | YOLO, Faster R-CNN |
| Klassifikation | Dokumentenprüfung, Sortierung | ResNet, EfficientNet |
| Segmentierung | Medizinische Bildgebung | U-Net, Mask R-CNN |
| 3D-Rekonstruktion | XR-Anwendungen, Schulungen | NeRF, Structure from Motion |
Für Technologietrends im Training spielt Computer Vision eine wachsende Rolle. Im Bildungswesen ermöglicht sie beispielsweise automatisierte Auswertungen von Lernvideos, adaptive Lernumgebungen oder immersive AR-Erlebnisse, bei denen das System auf die reale Umgebung reagiert. Unternehmen nutzen sie für Prozessautomatisierung, Sicherheitsüberwachung und die Qualitätssicherung. Bildungswesen mit 3D-Visualisierung zeigt eindrucksvoll, wie diese Technologien bereits heute Lernprozesse verändern.
Interessanterweise wächst der Bedarf an Computer Vision Fachkräften rasant, weil Unternehmen erkennen, dass die Technologie nur dann ihren vollen Nutzen entfaltet, wenn sie von Menschen mit echtem Domänenwissen implementiert und betreut wird. Innovationen in der Bildung entstehen genau dort, wo technisches Verständnis auf pädagogische Expertise trifft.
Typische Herausforderungen: Edge Cases und Domain Shift
Die häufigste Fehlerquelle beim produktiven Einsatz von Computer Vision ist ein Phänomen, das Fachleute als Domain Shift bezeichnen. Domain Shift bedeutet: Das Modell wurde auf bestimmten Daten trainiert, begegnet im realen Einsatz aber ganz anderen Bedingungen. Das Ergebnis? Plötzliche und oft überraschende Leistungsabfälle, die im Test nicht sichtbar waren.
Reale Variationen beeinflussen die Modellleistung stark: Wechselnde Beleuchtung, andere Kameras oder Kamerawinkel, unbekannte Hintergründe, Rauschen, Unschärfe oder Verdeckungen können dazu führen, dass ein scheinbar perfektes Modell im echten Betrieb gravierende Fehler macht. Das ist kein theoretisches Problem, sondern betrifft viele Projekte in der Praxis.
Wichtige Zahl: Studien zeigen, dass Modelle in kontrollierten Tests oft über 95 % Genauigkeit erzielen, im realen Einsatz aber auf 70 % oder weniger fallen können, wenn Domain Shift nicht aktiv adressiert wird.
Die häufigsten Auslöser für diesen Leistungsabfall lassen sich in fünf Kategorien einteilen:
- Beleuchtungsveränderungen: Ein Modell, das bei Tageslicht trainiert wurde, erkennt Objekte bei künstlichem Licht oder in der Dämmerung oft schlechter.
- Perspektivwechsel: Wird ein Objekt aus einem anderen Winkel gezeigt als im Training, sinkt die Erkennungsrate drastisch.
- Verdeckungen: Wenn ein Objekt teilweise verdeckt ist, fehlen dem Modell wichtige visuelle Hinweise, was zu Fehlklassifikationen führt.
- Bildqualität und Rauschen: Niedrige Auflösung, Kompressionsartefakte oder Kamerarauschen beeinflussen die Feature-Extraktion erheblich.
- Neue Hintergründe und Kontexte: Objekte vor unbekannten Hintergründen können als fremd eingestuft oder schlicht übersehen werden.
Für Unternehmen und Bildungseinrichtungen, die XR-Technologien und Sicherheit kombinieren, ist dieses Wissen besonders wertvoll. Ein VR-Sicherheitstraining, das auf Computer Vision basiert, muss robust gegenüber diesen Variationen sein, sonst entstehen Lücken, die im Ernstfall teuer werden können.
Strategien zur Steigerung der Robustheit:
- Datenaugmentation: Trainingsdaten werden künstlich variiert (Helligkeit, Rotation, Rauschen), damit das Modell mehr Variationen kennt.
- Domain Adaptation: Spezielle Techniken passen das Modell an neue Domänen an, ohne alles von Grund auf neu zu trainieren.
- Ensemble-Methoden: Mehrere Modelle werden kombiniert, um die Robustheit bei Edge Cases zu erhöhen.
- Kontinuierliches Monitoring: Im Produktivbetrieb werden Fehlerfälle systematisch erfasst und für Nachtraining genutzt.
Profi-Tipp: Sammelt ihr reale Bilder aus eurem geplanten Einsatzumfeld, bevor ihr ein Modell trainiert. Selbst 200 bis 300 repräsentative Bilder aus der echten Produktionsumgebung sind wertvoller als tausende Bilder aus dem Internet. VR-Sicherheitstraining zeigt, wie gezielte Vorbereitung die Lernzeit und Fehlerquote massiv reduziert. Ähnlich gilt das für Computer Vision: Qualität der Trainingsdaten schlägt Quantität.
Gerade VR-Sicherheit für Unternehmen profitiert von robustem Computer Vision, weil Echtzeit-Erkennung von Situationen und Personen zuverlässig funktionieren muss, um echten Mehrwert zu bieten.

Benchmarking und Evaluierung: Leistung richtig messen
Ein häufiger Fehler bei der Einführung von Computer Vision ist es, einem Modell zu vertrauen, weil es auf einem bekannten Benchmark gut abschneidet. Benchmarks wie ImageNet oder COCO sind wertvoll, spiegeln aber nicht automatisch die Leistung in eurer spezifischen Anwendungsdomäne wider.
Schwankende Performance je nach Domäne ist kein Ausnahmefall, sondern die Regel: Der Multi-Domain-Benchmark ODverse33 zeigt eindrucksvoll, dass neuere Architekturen nicht automatisch in allen Domänen besser sind und die Leistung je nach Datendomäne und Setup stark variieren kann. Das bedeutet: Wer ein Modell für Qualitätskontrolle in der Fertigung einsetzt, braucht fertigungsspezifische Tests, nicht nur allgemeine Benchmark-Ergebnisse.
„Ein Modell, das auf einer Benchmark ‘gewinnt’, kann in eurer Fabrik dennoch versagen. Die Domäne entscheidet."
Worauf kommt es bei der richtigen Evaluierung an?
- Domänenspezifische Testdaten: Verwendet Bilder und Szenarien, die eurem realen Einsatzumfeld so nah wie möglich kommen.
- Mehrere Metriken: Verlasst euch nicht nur auf Genauigkeit (Accuracy). Metriken wie Precision, Recall, F1-Score und Mean Average Precision (mAP) geben ein vollständigeres Bild.
- Fehleranalyse: Welche Fehler macht das Modell? Systematische Fehler (immer bei bestimmten Objekten oder Bedingungen) sind gefährlicher als zufällige.
- Latenz und Ressourcenbedarf: In vielen Praxisanwendungen ist Echtzeitverarbeitung gefragt. Ein Modell, das 98 % Genauigkeit hat, aber drei Sekunden pro Bild braucht, ist für Echtzeit-Sicherheitsanwendungen ungeeignet.
| Metrik | Was sie misst | Wann besonders wichtig |
|---|---|---|
| Accuracy | Anteil richtiger Vorhersagen | Ausgewogene Klassen |
| Precision | Anteil korrekter positiver Treffer | Wenn falsche Alarme teuer sind |
| Recall | Anteil erkannter positiver Fälle | Wenn verpasste Fälle teuer sind |
| F1-Score | Harmonisches Mittel aus Precision und Recall | Unausgewogene Datensätze |
| mAP | Mittlere Erkennungsgenauigkeit über Schwellwerte | Objekterkennung (Detection) |
KI im VR-Training zeigt, wie diese Prinzipien in der Praxis umgesetzt werden können. Wenn Computer Vision in immersiven Trainingsumgebungen eingesetzt wird, müssen die Evaluierungskriterien klar definiert sein, bevor das System live geht. Effizientes Training mit VR profitiert direkt von dieser sorgfältigen Herangehensweise.
Ein weiterer wichtiger Punkt: Benchmarking ist kein einmaliges Ereignis. Modelle müssen regelmäßig neu bewertet werden, weil sich die Einsatzbedingungen im Laufe der Zeit ändern. VR-Simulationen für Sicherheit illustrieren gut, warum kontinuierliche Qualitätssicherung in sicherheitskritischen Anwendungen unverzichtbar ist.
Computer Vision im Alltag: Praxisbeispiele und Anwendungsszenarien
Genug Theorie. Schauen wir uns an, wo Computer Vision heute schon wirklich eingesetzt wird und welche konkreten Vorteile Unternehmen und Bildungseinrichtungen davon haben.
Qualitätskontrolle und Automatisierung in der Industrie ist einer der reifsten Anwendungsbereiche. Kameras an Produktionslinien erkennen Defekte, Maßabweichungen oder Fremdkörper schneller und zuverlässiger als das menschliche Auge, wenn sie richtig konfiguriert sind. Unternehmen berichten von Einsparungen im zweistelligen Prozentbereich bei Ausschuss und Nacharbeit.
Objekterkennung für Sicherheit und Zutrittskontrolle ist ein weiteres wachsendes Feld. Kameras erkennen unberechtigte Personen, gefährliche Situationen oder das Fehlen von Schutzausrüstung in Echtzeit. Das schützt nicht nur Sachwerte, sondern vor allem Menschen.
AR-gestützte Lern- und Kommunikationslösungen kombinieren Computer Vision mit Augmented Reality. Das Ergebnis sind Erlebnisse, bei denen digitale Inhalte exakt auf reale Objekte ausgerichtet werden, etwa ein 3D-Modell einer Maschine, das direkt über dem echten Gerät eingeblendet wird. Für 3D-Visualisierung im Training ist diese Kombination besonders kraftvoll.
In Bildungseinrichtungen ermöglicht Computer Vision personalisierte Lernangebote. Systeme erkennen, welche Schritte ein Lernender ausführt, und geben in Echtzeit Feedback. Das ist besonders im Bereich praktischer Schulungen, etwa in Medizin, Technik oder Handwerk, ein echter Gamechanger.
Praxis-Tipps für die erfolgreiche Implementierung:
- Beginnt mit einem klar abgegrenzten Anwendungsfall, nicht mit einem allgemeinen „wir wollen KI nutzen."
- Definiert vorher, was Erfolg bedeutet: Welche Fehlerrate ist akzeptabel?
- Plant von Anfang an Budget für Datenbeschaffung und -annotation ein. Das wird oft unterschätzt.
- Testet das System in der echten Umgebung, bevor ihr es live schaltet.
- Baut ein Feedback-System ein, damit das Modell aus Fehlern lernen kann.
Profi-Tipp: Wer Computer Vision mit VR oder AR kombiniert, schafft immersive Trainingswelten, die nicht nur effizienter sind, sondern auch nachhaltiger im Lernerfolg. Technologietrends in der Bildung zeigt, wie diese Kombination bereits heute die Lernzeit um bis zu 40 % reduzieren kann.
Eine wichtige Erkenntnis, die oft übersehen wird: Maschinen sehen anders als Menschen. „Sicht wie Menschen" ist nicht gleichbedeutend mit „Messziele optimieren." Modelle scheitern bei Verdeckungen oder unklaren Informationen deutlich häufiger als Menschen und benötigen deshalb geeignete Benchmarks und robuste Strategien für Unsicherheit und Fehlerfälle. Business-Technologien im Training liefert dazu wertvolle Einblicke, wie moderne Unternehmen diese Herausforderungen meistern.
Redaktioneller Einblick: Die unterschätzte Komplexität von Computer Vision
Wir erleben es regelmäßig: Unternehmen und Schulen kommen zu uns mit der Erwartung, Computer Vision sei eine Art digitales Auge, das einfach funktioniert. Die Enttäuschung folgt oft schnell, wenn das erste Modell im Praxiseinsatz strauchelt.
Der größte Mythos ist der Vergleich mit menschlicher Sicht. Maschinensicht optimiert Messziele, nicht Verstehen. Ein Mensch erkennt eine Katze auch dann, wenn sie halb verdeckt, schlecht beleuchtet und unscharf ist. Ein Modell kann dabei vollständig versagen, weil ihm der Kontext fehlt, den wir als Menschen intuitiv nutzen. Das ist keine Schwäche, die bald behoben wird. Es ist eine fundamentale Eigenschaft dieser Technologie.
Was bedeutet das für Entscheider in Unternehmen und Bildung? Es bedeutet: Wer Computer Vision einführt, braucht klare Anwendungsgrenzen, robuste Evaluierungsprozesse und einen Plan für Fehlerfälle. Die Technologie ist mächtig. Aber nur dort, wo sie gezielt und mit realistischen Erwartungen eingesetzt wird, entfaltet sie echten Wert. Wir empfehlen, Technologie-Trends für Bildung als strategischen Kompass zu nutzen, um fundierte Entscheidungen zu treffen. Die Kombination aus Neugier, kritischem Denken und technologischem Verständnis ist das, was erfolgreiche Implementierungen von gescheiterten unterscheidet.
Mehr Wert durch AR und Computer Vision: Lösungen für Unternehmen und Bildung
Computer Vision ist ein kraftvolles Werkzeug. Aber ihr volles Potenzial entfaltet es erst in Kombination mit AR, VR und maßgeschneiderten KI-Lösungen. Genau das ist unser Feld bei Amlogy. 🚀

Ob ihr AR-Anwendungen in eure bestehenden Prozesse integrieren, den Lernerfolg durch AR steigern oder die Vorteile von AR konkret für euren Geschäftsalltag nutzen wollt: Wir begleiten euch Schritt für Schritt. Unser Guide zum AR-Lösungen integrieren zeigt, wie der Einstieg gelingt, ohne typische Fallstricke. Meldet euch für eine kostenlose Erstberatung und lasst uns gemeinsam euren nächsten digitalen Schritt planen. 👇
Häufig gestellte Fragen
Was bedeutet Domain Shift bei Computer Vision?
Domain Shift als Fehlerquelle bezeichnet den Unterschied zwischen den Bedingungen, unter denen ein Modell trainiert wurde, und den realen Einsatzbedingungen, was zu plötzlichen und oft erheblichen Leistungsabfällen führen kann.
Welche typischen Aufgaben kann Computer Vision automatisieren?
Pipeline und Aufgaben in Computer Vision umfassen Erkennung, Klassifikation, Segmentierung und 3D-Rekonstruktion von Objekten, die alle in industriellen und bildungsbezogenen Anwendungen eingesetzt werden.
Warum sind Benchmarks für Computer Vision wichtig?
Multi-Domain-Benchmarks wie ODverse33 zeigen, dass Benchmarks helfen, die Leistung von Modellen objektiv und domänenspezifisch zu vergleichen, um Fehlentscheidungen bei der Modellauswahl zu vermeiden.
Wo wird Computer Vision im Bildungsbereich eingesetzt?
Computer Vision wird im Bildungsbereich für automatisierte Bildanalyse, AR-gestützte Lernprozesse, Echtzeit-Feedback bei praktischen Übungen und die Optimierung von Schulungsprozessen eingesetzt.
Was ist der Unterschied zwischen menschlicher Sicht und Computer Vision?
Menschliche versus maschinelle Sicht unterscheidet sich fundamental: Menschliche Sicht ist flexibel, kontextbasiert und robust gegenüber Unvollständigkeit, während Computer Vision auf messbare Ziele optimiert und bei Unsicherheit oder Verdeckungen deutlich anfälliger für Fehler ist.
Empfehlung
- 3D-Visualisierung: Definition, Nutzen und Einsatz in Training – Amlogy AR|VR
- Unterschied AR und VR: Mehrwert für Bildung 2026 – Amlogy AR|VR
- Smarte Lernumgebungen: Definition, Funktionen und AR/VR-Praxis – Amlogy AR|VR
- Was ist KI? Grundlagen, Nutzen und Anwendung 2026 – Amlogy AR|VR